技术文章

2015-07-14
时下业界利用深度学习算法来训练卷积神经网络(CNN),以期实现智能化程度更高的移动设备,这可能需要以全新方法来设计处理器架构。但是,巧妙地充分利用现有的技术,也可帮助我们进一步走向具备真正智能认知能力的设备,并能够完全重新定义用户体验。
Nvidia在三月的GPU技术大会上使用汽车和先进驾驶辅助系统(ADAS)作为应用重点,配合Elon Musk的意见和评论,希望表明自动驾驶汽车的挑战几乎已被完全克服了。另一方面,随着时间的推移,加上一些着眼于降低功耗的调整与改良,我看到无处不在的3D感知、3D跟踪,以及图像搜索等许多技术和应用正在快速进入智能手机,以及其他以电源或电池供电的嵌入式系统中。
结合用于侦测运动和音频信号的传感器、快速的存储器访问 ,以及高功效的数据处理方法,这些系统可以拥有真正的“认知”能力,甚至在不远的将来构成一个用于人工智能移动设备的平台。同时,重要的是优化现有的架构来实现“智能视觉”功能,比如3D深度图和感知、物体识别以及增强现实,还有一些核心的计算图像学功能,比如图像缩放、HDR、图像再对焦,以及微光图像增强。
随着许多图像处理与增强功能也都使用计算机视觉技术,计算机视觉和图像处理技术之间的区别正在变得越来越模糊。最直接的例子就是多帧图像增强功能,比如HDR、图像缩放与再对焦--拍摄多个连续的图像,然后将它们融合在一起,得到更高质量的画面。
虽然我们称之为“图像增强”,但这其实涉及大量的计算机视觉处理来“register”图像,既完成两帧或三帧画面之间的匹配。现在,用户认为这种基本功能是理所当然的,但其实它需要非常强大的处理能力,使得对于专门的、高性能的数字信号处理 (DSP)的需求将会增加。
高通公司(Qualcomm) 在Uplinq 2013上发布了文章,很好地描绘出用于各种不同处理功能的像素功率和时间关系。图中展示了三个处理器,包括一个在1.2 GHz下运行的单核CPU、一个四核CPU,以及一个在690 MHz下运行的DSP。
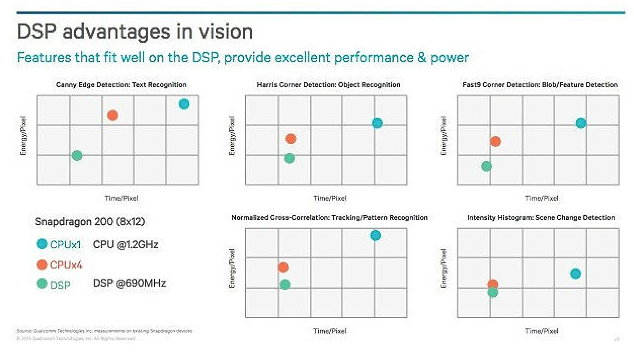
图1:描绘不同处理器在处理每个像素时需要的处理能力和时间,表明了DSP结合CPU用于视觉处理的优势。为了优化功耗和性能,结合CPU、DSP和GPU可能是总体来说最好的方法。
图表表明DSP在仅略微超过CPU一半的时钟频率下运行,便能够在图像处理上达到相同的效果,提供了潜在的性能增益,同时节省了更多的功耗(功率= 电容 x 电压2 x 频率,或者P=CV2xF)。
然而,随着我们转向在移动平台上实现类似人类的视觉、人工智能和增强现实应用,可能需要重新思考所需的处理架构。结合传感器融合和先进深度学习算法(比如CNN),这些非常先进的计算密集型应用将提供更具环境感知和情境感知的用户体验,但是在电池寿命方面却要作出取舍。
设计人员面临的挑战,是一方面要实现具有智能感知能力的设备,同时在另一方面维持可接受的电池寿命。有几种方法来实现这一点。例如,可以使用来自高通或Nvidia的GPU来支持CPU。这已经在许多智能手机中实现了。然而,降低功耗这一持续性的强制需求驱使我们将特定的处理密集型功能分散给针对视觉处理进行优化的DSP处理器。在处理物体识别和跟踪时,对比当下最先进的GPU簇群,使用这种方法可以节省高达9倍的功耗。
然而,即使具备这种功耗水平,移动设备仍然不太可能很快地使用面部识别来进行人群搜索,因为此功能对于处理能力的要求还是太高了。不过,低功耗处理器和经过特定优化的处理器架构的面世带来了希望,使得我们在这个领域内正在取得实质的进展。这类进展是MIT Technology Review将深度学习称为2013年十项技术突破之一的原因所在。除了GTC上进行了相关演示,微软、百度,以及Cognivue也展示了一些研究成果。此后,这个领域中还有其他长足发展。
此外,Aziana (澳大利亚)最近宣布与BrainChip(美国加州)合并,后者是专门以硬件方式实施人工智能的企业,并已经着眼于开发用于移动平台的人工智能。虽然支持强大处理能力的架构和超低功耗处理是至关重要的,但随着云连接变得更普及、更快捷,若我们将尽可能多的处理开销分配到云中,也是合乎情理的。这将会走向智能的处理性能分配。在云做最适合在云中处理的工作,在移动设备做最适合移动设备处理的工作,尽可能高效地依据架构分配功能,比如使用CPU来分配GPU和DSP之间的负载。用高通公司的说法,就是使用合适的引擎来做合适的工作。
